The first step of every statistical analysis you will perform is the population vs sample data check or to determine whether the data you are dealing with is a population or a sample.
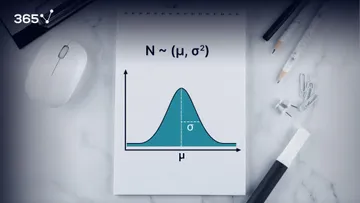
A population is the collection of all items of interest to our study and is usually denoted with an uppercase N. The numbers we’ve obtained when using a population are called parameters.
A sample is a subset of the population and is denoted with a lowercase n, and the numbers we’ve obtained when working with a sample are called statistics.
Now you know why the field we are studying is called statistics.
Let’s say we want to make a survey of the job prospects of the students studying at the New York University. What is the population?
You can simply walk into New York University and find every student, right? Well, probably, that would not be the population of NYU students. The population of interest includes not only the students on campus but also the ones at home, on exchange, abroad, distance education students, part-time students, even the ones who enrolled but are still at high school. Though exhaustive, even this list misses someone. Point taken. Populations are hard to define and hard to observe in real life. (In the meantime, if you're trying to get your first job after university, check out our article Data Science Resume for University Graduates.)
A sample, however, is much easier to contact.
It is less time consuming and less costly. Time and resources are the main reasons we prefer drawing samples, compared to analyzing an entire population. So, let’s draw a sample then.
As we first wanted to do, we can just go to the NYU campus. Next, let’s enter the canteen, because we know it will be full of people. We can then interview 50 of them. Cool!
This is a sample.
Good job!
But what are the chances these 50 people provide us answers that are a true representation of the whole university? Pretty slim, right. The sample is neither random nor representative.
A random sample is collected when each member of the sample is chosen from the population strictly by chance.
We must ensure each member is equally likely to be chosen.
Let’s go back to our example. We walked into the university canteen and violated both conditions. People were not chosen by chance; they were a group of NYU students who were there for lunch. Most members did not even get the chance to be chosen, as they were not on campus. Thus, we conclude the sample was not random.
What about representativeness of the sample?
A representative sample is a subset of the population that accurately reflects the members of the entire population.
Our sample was not random, but was it representative?
Well, it represented a group of people, but definitely not all students in the university. To be exact, it represented the people who have lunch at the university canteen. Had our survey been about job prospects of NYU students who eat in the university canteen, we would have done well. Speaking of job prospects, if you're interested in a data science career, check out our article 15 Data Science Consulting Companies Hiring Now.
By now, you must be wondering how to draw a sample that is both random and representative. Well, the safest way would be to get access to the student database and contact individuals in a random manner. However, such surveys are almost impossible to conduct without assistance from the university!
We said populations are hard to define and observe. Then, we saw that sampling is difficult. But samples have two big advantages. First, after you have experience, it is not that hard to recognize if a sample is representative. And, second, statistical tests are designed to work with incomplete data; thus, making a small mistake while sampling is not always a problem.
We've got you covered with a population vs sample explanation. Now, if you're curious about Lindley's paradox, check out our article Bayesian vs Frequentist Approach: Same Data, Opposite Results.
Watch our Next Video: The Simple Linear Regression Model.
Enroll in our Statistics course.
Check out our tutorials The Differences between Correlation and Regression,