Error tokenizing data, my juypiter notebook is always giving this error
data = pd.read_csv('http://localhost:8888/edit/Documents/1.01.%20Simple%20linear%20regression.csv')
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_5980\339079603.py in <module>
----> 1 data = pd.read_csv('http://localhost:8888/edit/Documents/1.01.%20Simple%20linear%20regression.csv')
~\anaconda3\lib\site-packages\pandas\util\_decorators.py in wrapper(*args, **kwargs)
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
312
313 return wrapper
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
676 kwds.update(kwds_defaults)
677
--> 678 return _read(filepath_or_buffer, kwds)
679
680
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in _read(filepath_or_buffer, kwds)
579
580 with parser:
--> 581 return parser.read(nrows)
582
583
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in read(self, nrows)
1251 nrows = validate_integer("nrows", nrows)
1252 try:
-> 1253 index, columns, col_dict = self._engine.read(nrows)
1254 except Exception:
1255 self.close()
~\anaconda3\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py in read(self, nrows)
223 try:
224 if self.low_memory:
--> 225 chunks = self._reader.read_low_memory(nrows)
226 # destructive to chunks
227 data = _concatenate_chunks(chunks)
~\anaconda3\lib\site-packages\pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.read_low_memory()
~\anaconda3\lib\site-packages\pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows()
~\anaconda3\lib\site-packages\pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._tokenize_rows()
~\anaconda3\lib\site-packages\pandas\_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error()
ParserError: Error tokenizing data. C error: Expected 1 fields in line 12, saw 2
1 answers ( 0 marked as helpful)
Hey Tendai,
Thank you for reaching out!
Put your Jupyter notebook file and the "1.01. Simple linear regression.csv" file in the same folder, as shown below:
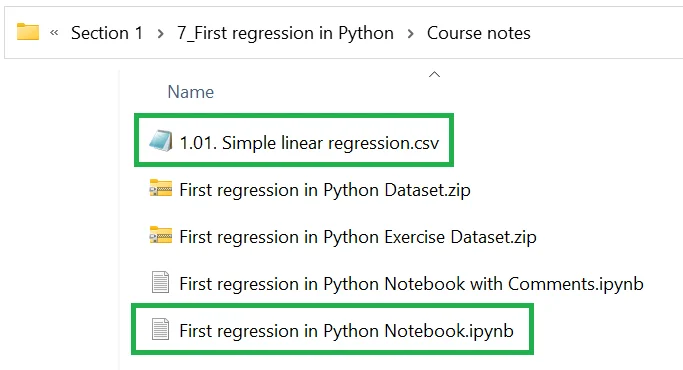
Then, write your code as shown in the lecture, namely:
data = pd.read_csv("1.01. Simple linear regression.csv")
Hope this helps!
Kind regards,
365 Hristina