Kleio T.
After 365:
Bioinformatics and Neuroinformatics student
See all reviews
Master advanced statistical techniques and predictive modeling with Python. Acquire the essential skills for aspiring data scientists.





Skill level:
Duration:
CPE credits:
Accredited

Bringing real-world expertise from leading global companies


Bachelor's degree, International Economics, Management, and Finance

Description
Machine Learning in Python builds upon the statistical knowledge you gained earlier in the program. This course focuses on predictive modelling and enters multidimensional spaces which require an understanding of mathematical methods, transformations, and distributions. We will introduce these concepts, as well as complex means of analysis such as clustering, factoring, Bayesian inference, and decision theory, while also allowing you to exercise your Python programming skills.
___
Need a little extra help growing your new skills? Meet Guidy, your AI study buddy for real-time support inside any software or website. Try for free.
Curriculum
Free lessons

1.1 Course Introduction
1 min

1.3 The linear regression model
6 min
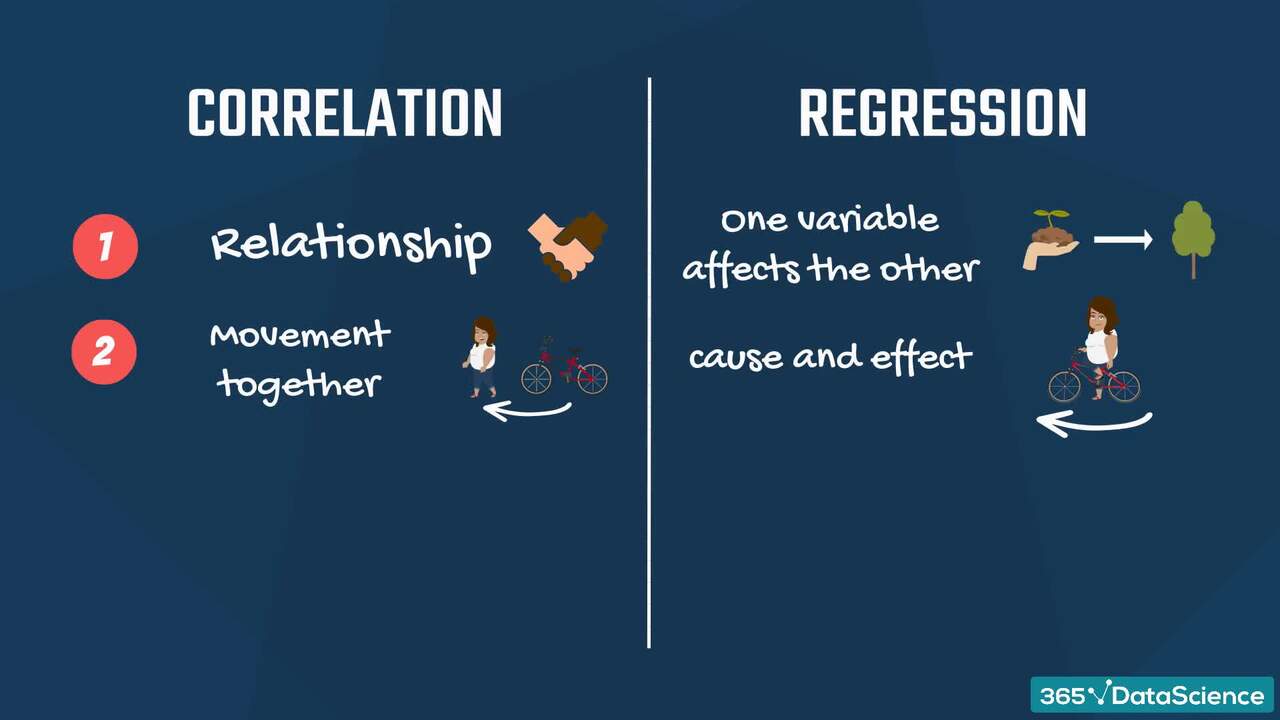
1.5 Correlation vs regression
2 min
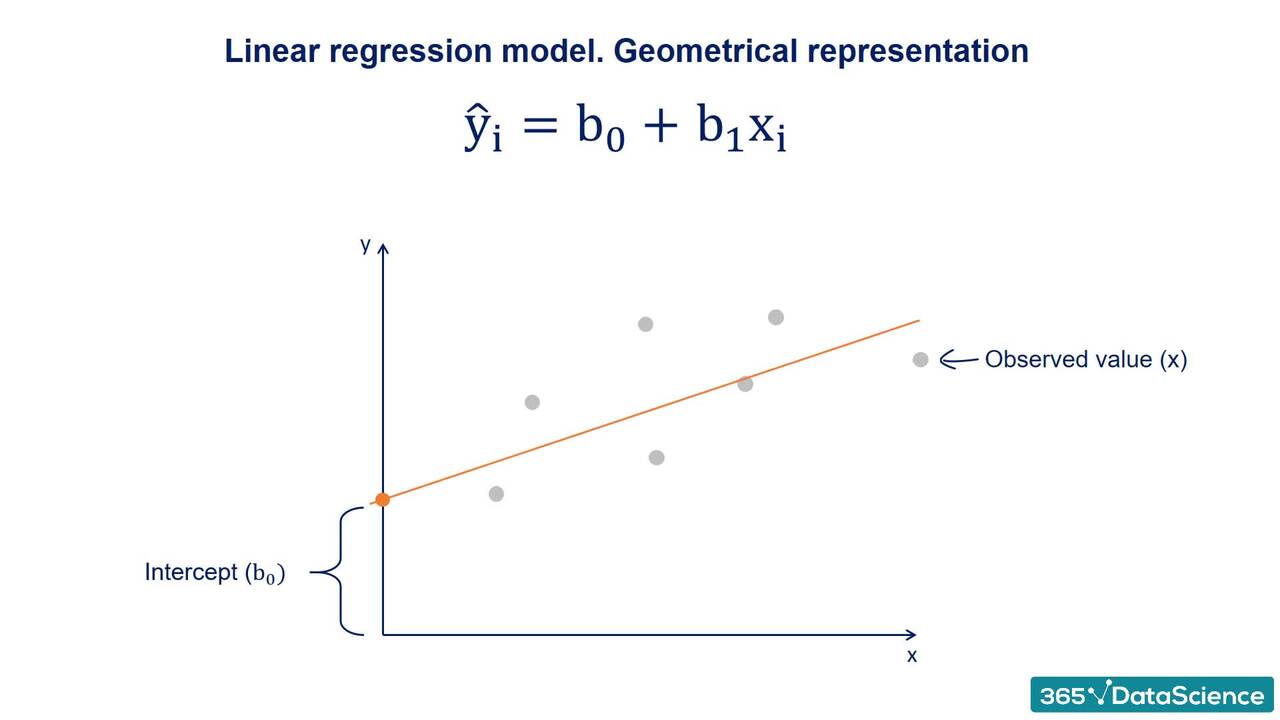
1.6 Geometrical representation of the Linear Regression Model
1 min
1.8 Setting up the Environment
1 min
1.9 Python packages installation
5 min
94%
of AI and data science graduates
successfully change
96%
of our students recommend
$29,000
average salary increase
ACCREDITED certificates
Craft a resume and LinkedIn profile you’re proud of—featuring certificates recognized by leading global
institutions.
Earn CPE-accredited credentials that showcase your dedication, growth, and essential skills—the qualities
employers value most.
Certificates are included with the Self-study learning plan.

How it WORKS
Student REVIEWS