Pedro A.
Before 365:
Industrial Engineer | NIBOL
After 365:
Data Manager | NIBOL
See all reviews
Blend credit risk modeling skills with Python programming: Learn how to estimate a bank’s loan portfolio's expected loss





Skill level:
Duration:
CPE credits:
Accredited

Bringing real-world expertise from leading global companies


Doctorate (PhD), Economics & Business Administration

Description
Curriculum
Free lessons
1.1 What does the course cover
5 min

1.2 What is credit risk and why is it important?
5 min

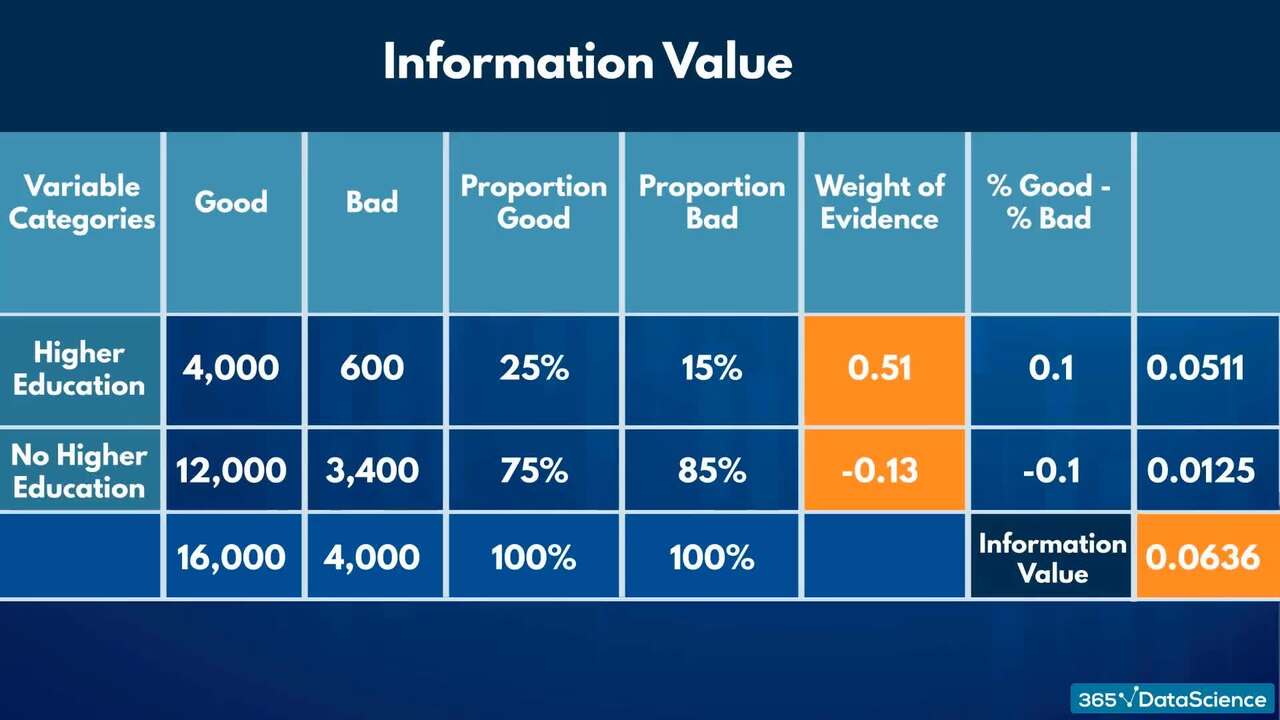
1.3 Expected loss (EL) and its components: PD, LGD and EAD
4 min

1.4 Capital adequacy, regulations, and the Basel II accord
5 min
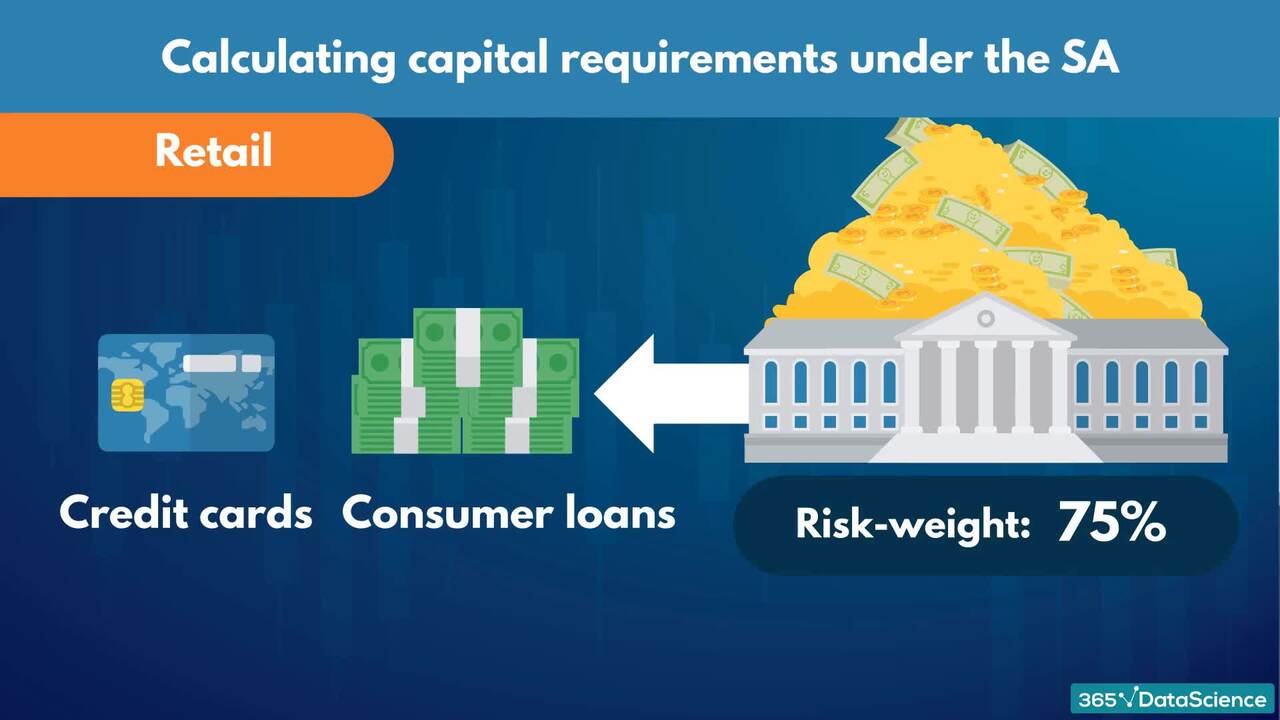
1.5 Basel II approaches: SA, F-IRB, and A-IRB
10 min
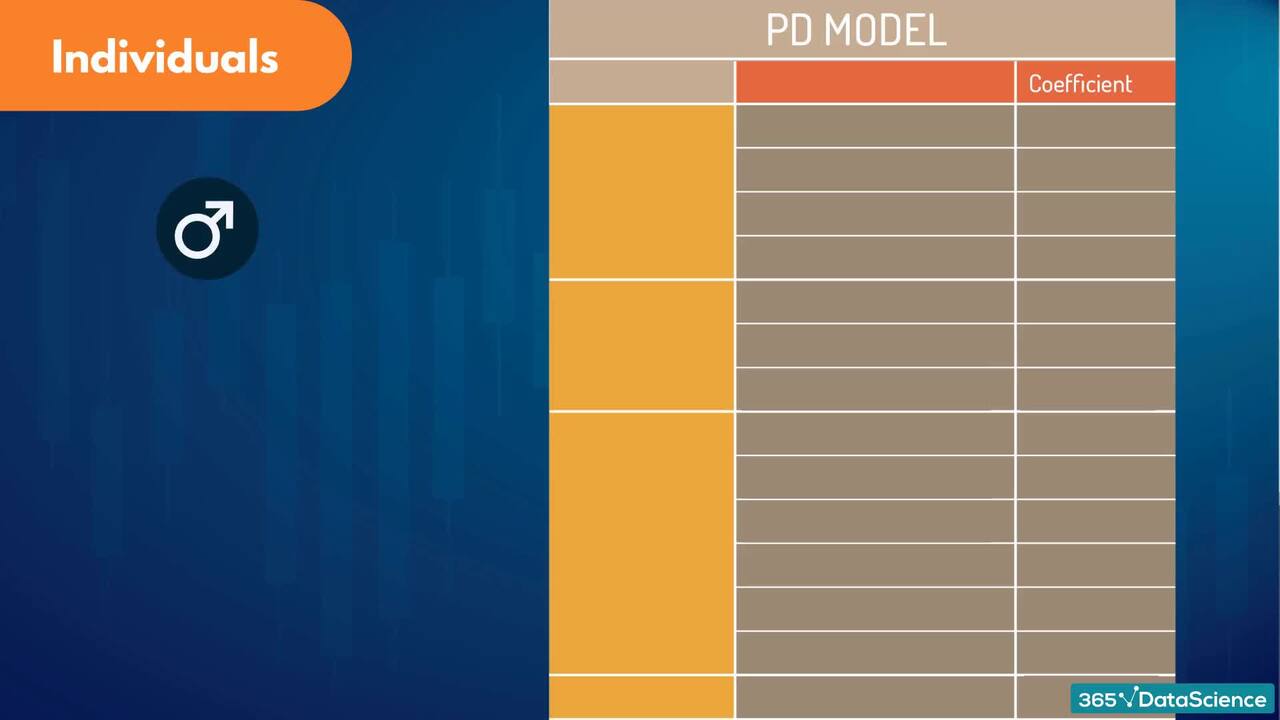
1.6 Different facility types (asset classes) and credit risk modeling approaches
9 min
94%
of AI and data science graduates
successfully change
96%
of our students recommend
$29,000
average salary increase
ACCREDITED certificates
Craft a resume and LinkedIn profile you’re proud of—featuring certificates recognized by leading global
institutions.
Earn CPE-accredited credentials that showcase your dedication, growth, and essential skills—the qualities
employers value most.
Certificates are included with the Self-study learning plan.

How it WORKS
Student REVIEWS