Kleio T.
After 365:
Bioinformatics and Neuroinformatics student
See all reviews
Master deep learning in Python with TensorFlow 2: Apply neural networks to solve real-world data science challenges





Skill level:
Duration:
CPE credits:
Accredited

Bringing real-world expertise from leading global companies


Master's degree, Computer Science


Bringing real-world expertise from leading global companies


Bachelor's degree, International Economics, Management, and Finance

Description
Curriculum
Free lessons

1.1 Why machine learning
7 min

2.1 Introduction to neural networks
4 min

2.3 Training the model theory
3 min

2.5 Types of machine learning
4 min

2.7 The linear model
3 min
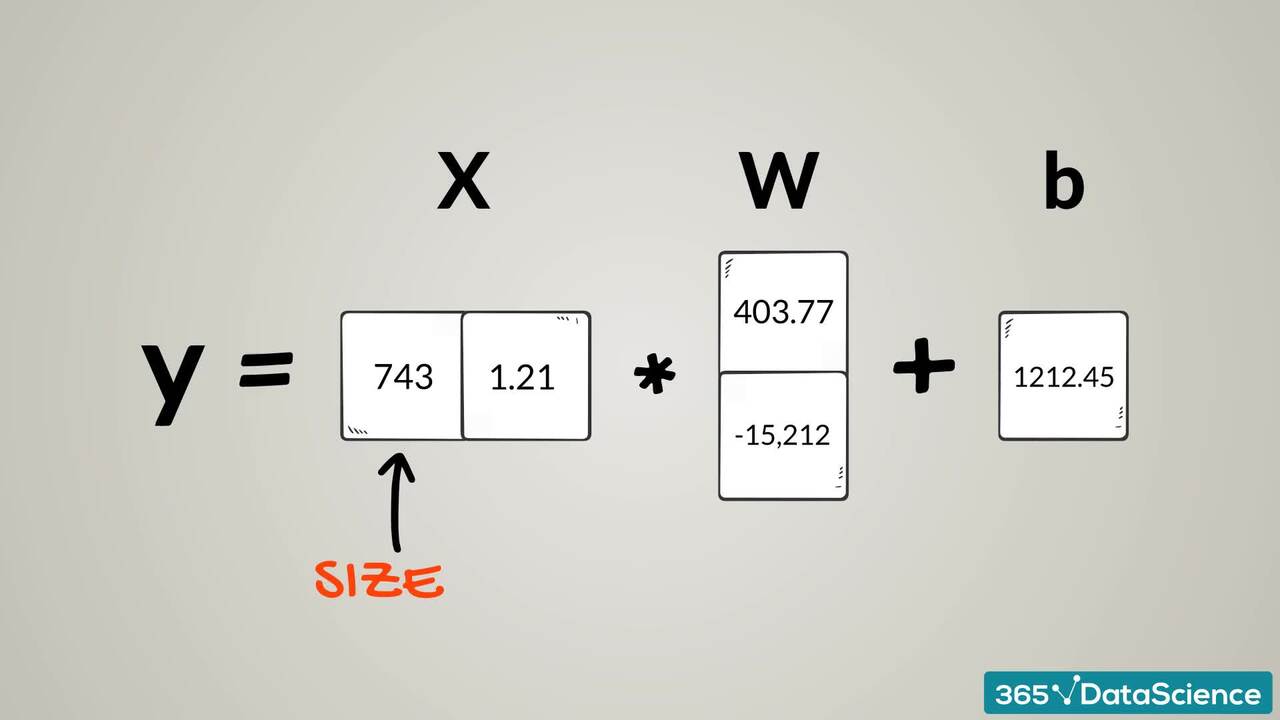
2.9 The linear model. Multiple inputs.
2 min
#1 most reviewed
$29,000
average salary increase
9 in 10
of our graduates landed a new AI & data job
ACCREDITED certificates
Craft a resume and LinkedIn profile you’re proud of—featuring certificates recognized by leading global
institutions.
Earn CPE-accredited credentials that showcase your dedication, growth, and essential skills—the qualities
employers value most.
Certificates are included with the Self-study learning plan.

How it WORKS
Student REVIEWS