M K Junayed P.
Before 365:
Product development | Bikroy
After 365:
Assistant Manager (Analyst) | Green Delta Insurance PLC
See all reviews
Master speech recognition—the technology that enables machines to understand human speech by converting voice into readable data. Utilize Python speech recognition tools to transcribe audio to text with cutting-edge AI models.





Skill level:
Duration:
CPE credits:
Accredited

Bringing real-world expertise from leading global companies

Master's degree, Sound Engineering

Description
Curriculum
Free lessons

1.1 Welcome to the World of Speech Recognition
5 min

1.2 Course Approach
4 min
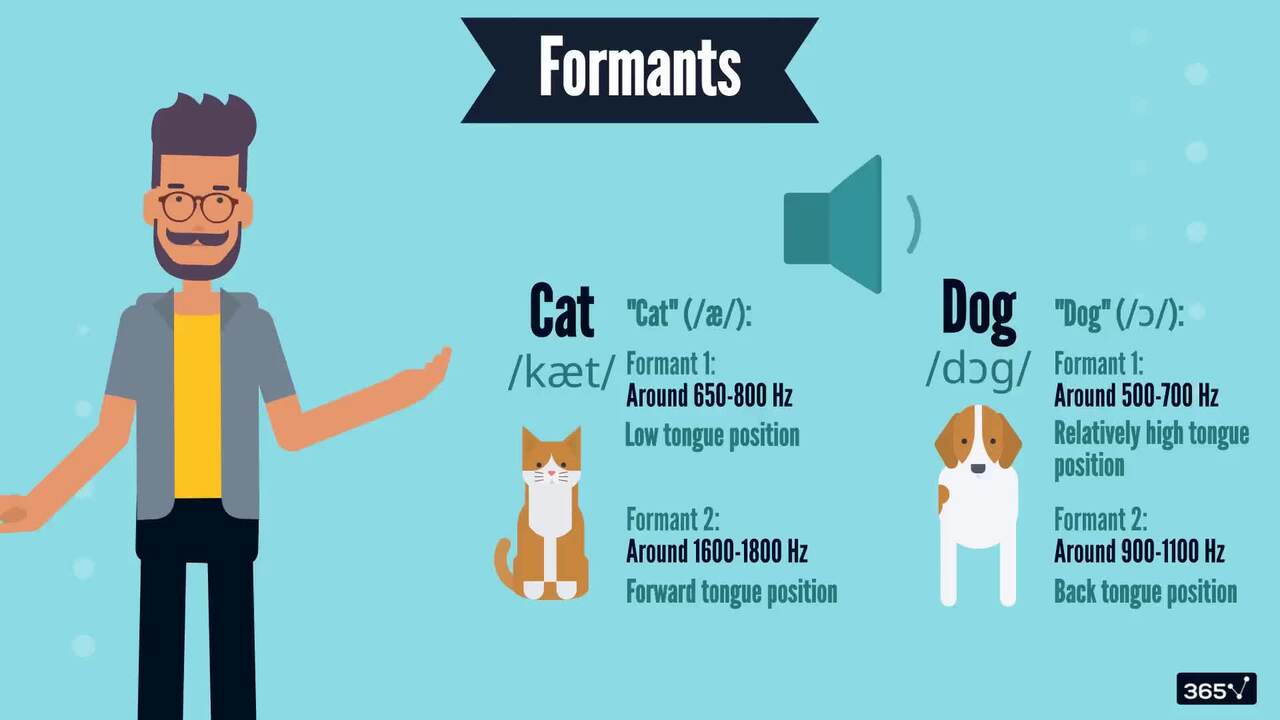
1.3 How It All Started: Formants, Harmonics, and Phonemes
3 min

1.5 Development and Evolution
4 min
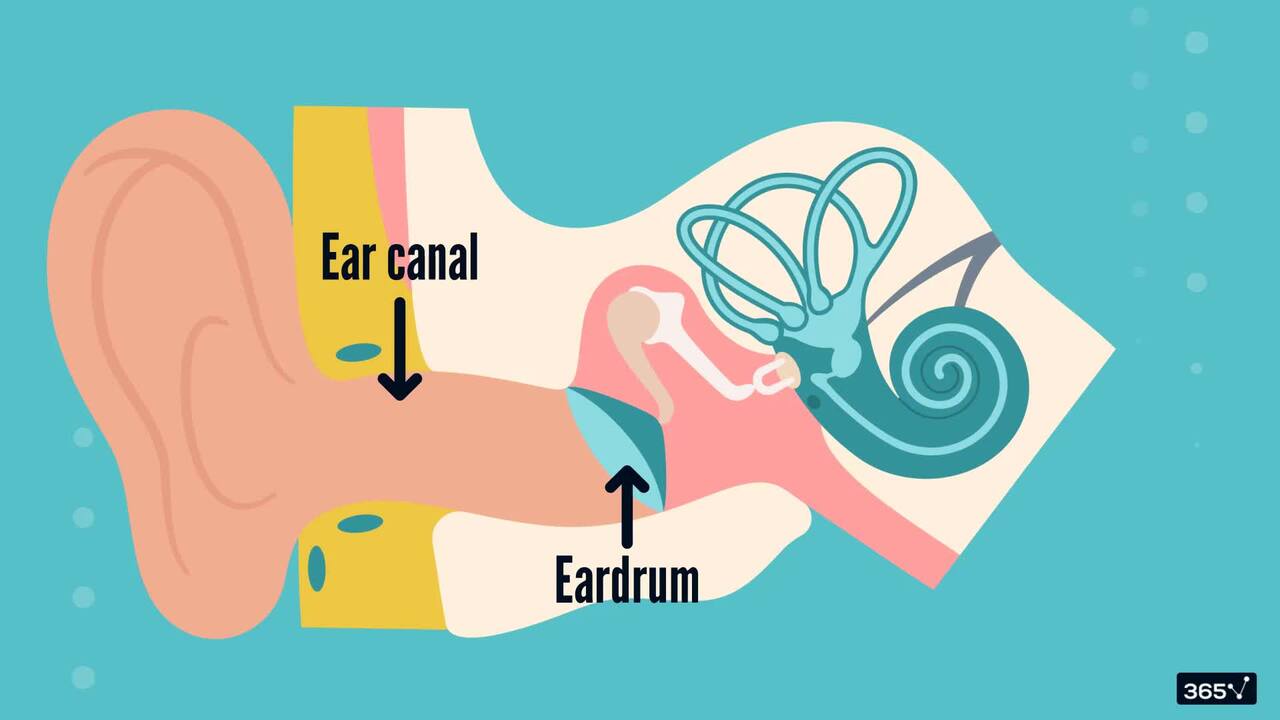
2.1 How Do Humans Recognize Speech?
3 min

2.3 Fundamentals of Sound and Sound Waves
3 min
94%
of AI and data science graduates
successfully change
$29,000
average salary increase
9 in 10
of our graduates landed a new AI & data job
ACCREDITED certificates
Craft a resume and LinkedIn profile you’re proud of—featuring certificates recognized by leading global
institutions.
Earn CPE-accredited credentials that showcase your dedication, growth, and essential skills—the qualities
employers value most.
Certificates are included with the Self-study learning plan.

How it WORKS
Student REVIEWS