Resolved: duplicate records
Hi Bwende!
Thanks for reaching out.
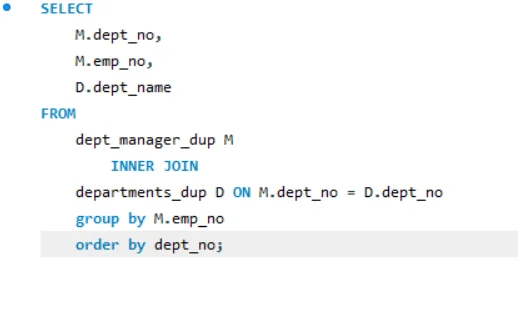
When you use the GROUP BY clause, you group the results by each employee number.
However, in your SELECT, you also include dept_no and dept_name, but you don’t use any function like MIN(), MAX() or COUNT() to tell the database how to choose values for them. Because of that, MySQL just picks any value it finds from the group — not always the one you expect. That’s why your result looks the same, even with GROUP BY.
If your goal is to remove duplicate rows, the correct way is to use:SELECT DISTINCT M.dept_no, M.emp_no, D.dept_name
FROM dept_manager_dup M
JOIN departments_dup D ON M.dept_no = D.dept_no
ORDER BY dept_no;
The DISTINCT keyword removes exact duplicate rows from the result.
Note: Please, use small letters for table aliases like m and d . This is a common style in SQL and makes your code easier to read.
Hope this helps.
Best,
Tsvetelin