
 Hello, fellow scrapers! In this tutorial, we will talk about request headers – what they are, in what way they may restrict our scraping and how to use them to our advantage. We will also discuss a special type of a request header – cookies.
Hello, fellow scrapers! In this tutorial, we will talk about request headers – what they are, in what way they may restrict our scraping and how to use them to our advantage. We will also discuss a special type of a request header – cookies.
So, what is a header in the context of a request?
Well, when you’re sending a request to a server you’re not just saying: ‘Hey, give me that info, please’. You are also providing information about the request itself – information, such as the encoding and language of the expected response, the length and type of data provided, who is making the request and so on. These pieces of information, referred to as headers, are intended to make communications on the web easier and more reliable, as the server has a better idea of how to respond.
Okay. But the question remains - how are these headers specified?
Well, every type of header information is contained in a standardized header field. Two of the most common header fields are the ‘User-Agent’ and ‘cookie’. Let’s take a deeper look into those.
Request Headers: What is a user agent string?
When a software sends a request, it often identifies itself, its application type, operating system, software vendor, or software version, by submitting a characteristic identification string. This string is referred to as a “user agent string”. You can think of it as an ID card containing some basic information.
All browsers, as well as some popular crawlers and bots, such as ‘google bot’, have a unique ‘user agent string’ that they identify themselves with.
So how does this concern us, the scrapers?
Well, a lot of companies set up their servers in a way that allows them to identify the browser a client is using. In fact, most websites may look a tiny bit different in Chrome, Firefox, Safari and so on. Based on the browser, a specific version of the web page is sent to the client for optimal visual and computational performance. However, this may become an issue for us if we do not provide a proper ‘user agent string’.
There are two things that can happen in that case.
First of all, the server may be set up to send a default variant of a page if it doesn’t recognize the user agent.
In this situation, the HTML we are looking at in our browser may be different from what we receive as a response. The solution in this case, though, is pretty straightforward – exporting the HTML response to a local file and inspecting that one, instead of the browser version.
A more serious issue arises when the server decides to block all unrecognized traffic.
In that case, to continue scraping, we need to provide a legitimate user agent. Fortunately, all browsers’ user agent strings are available publicly on the internet. Thus, we can easily pretend to be a browser.
Let’s see how to do this in Python using the ‘requests’ package.
Incorporating different headers using ‘requests’ is actually a very simple job. All we have to do is supply them in a dictionary format to the ‘headers’ parameter.
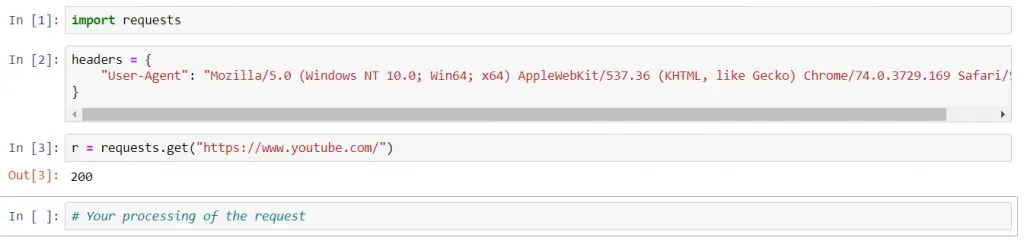
For instance, suppose we want to make a GET request to YouTube, pretending to be a client using Chrome. First, we need to find the User-Agent string of Chrome. A quick Google search yielded us this string:
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
Okay. We can save it in a dictionary with field name ‘User-Agent’.

Now, we can make a GET request using the usual ‘get()’ method of the package. The URL of the site we want to connect to is passed as a parameter. Normally, that would be all. ![]()
However, in order to incorporate the request headers, we can add them in dictionary form to the additional ‘headers’ parameter. In our case, we have saved the dictionary in the ‘header’ variable, so we pass that to the parameter.

That’s it. This request now contains a ‘User-Agent’ header field.
And here’s the full code:
By adding different fields to our dictionary, we can incorporate different headers into the request.
Dealing with Request Headers: What about the cookies?
If dealing with request headers is that simple, what is so special about the cookies?
Well, an HTTP cookie is a special type of request header that represents a small piece of data sent from a website and stored on the user's computer. It is different from other headers, as we are not the ones to choose it – it is the website that tells us how to set this field. Then, the cookie can be sent along with subsequent client requests.
Cookies were designed to be a reliable mechanism for websites to remember stateful information, such as items added in the shopping cart in an online store, or to record the user's browsing activity.
They can also be used to remember arbitrary pieces of information that the user previously entered into form fields, such as names, addresses, passwords, and credit-card numbers.
Cookies perform essential functions in the modern web.
Perhaps the most important one is the authentication cookie. It is the most common method used by web servers to know whether the user is logged in or not, and which account they are logged in with. This basically means that you are not required to sign in every time you open or reload a page.
Cookies are implemented a bit different from the ‘user agent’, as websites usually tell us how to set them the first time we visit a page.
Despite that, the awesome ‘requests’ package saves the day once again with its session class.
We can open a new session using this command.
![]()
Notice that we assign the session to a variable. Later, we can make requests through this variable. Every such request within that session will incorporate persistent cookies automatically. We don’t have to do anything. After we are done, we have to close the session. Here is an example code: 
Just remember that the request should be made through the session variable. You can find more about that in the official ‘requests’ documentation here.
You have now added the request headers weapon to your web scraping arsenal. Let us know how you implemented it in your practice in the comments below!
Eager to become a Web Scraping Pro? Check out the 365 Web Scraping and API Fundamentals in Python Course!
The course is part of the 365 Data Science Program. You can explore the curriculum or sign up 12 hours of beginner to advanced video content for free by clicking on the button below.








