Resolved: Quiz Question for Linear Regression Practical Example
Hey team,
I think there might be an error with the answers to this exam question. Please double check for me. Thanks!
-Justin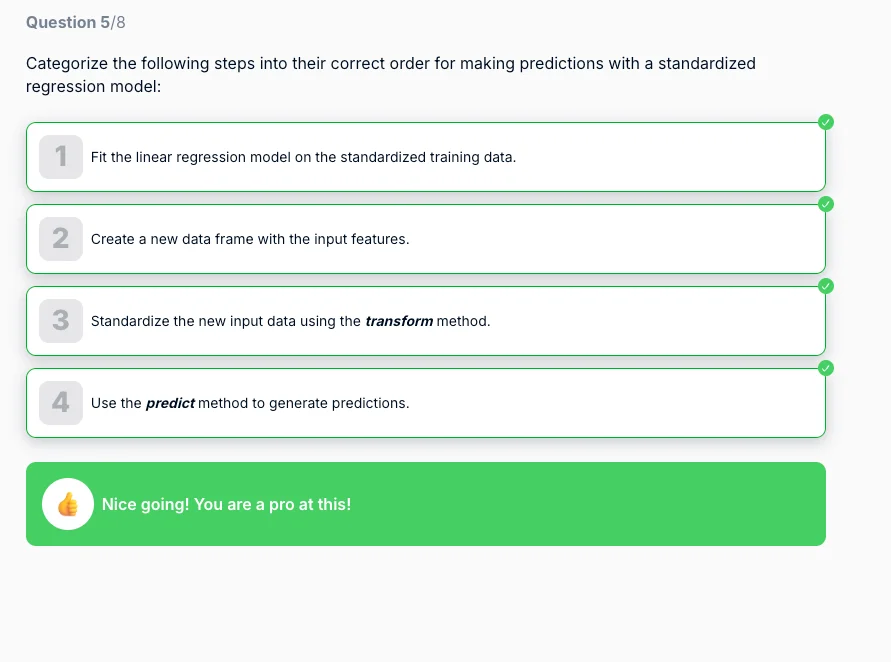
I think there might be an error with the answers to this exam question. Please double check for me. Thanks!
-Justin
6 answers ( 1 marked as helpful)
Hi Justin!
Thanks for reaching out.
The order in the exam is correct. First, you train the model on the standardized training data. When making predictions, you create your new input data, standardize it with the same scaler used during training, and then run the predict method. This way, the model sees data in the same format it was trained on and can give accurate predictions.
Can you share what you think might be wrong so we can look into it together? Thanks!
Best,
Ivan
Thanks for reaching out.
The order in the exam is correct. First, you train the model on the standardized training data. When making predictions, you create your new input data, standardize it with the same scaler used during training, and then run the predict method. This way, the model sees data in the same format it was trained on and can give accurate predictions.
Can you share what you think might be wrong so we can look into it together? Thanks!
Best,
Ivan
Thanks Ivan! When using train test split, we've already split the data into both training and test sets at the same time. As a result, it seemed to me that creating the new data frame with the input features could go before fitting the linear regression on the standardized training data. This is because training and test data sets are created at the same time. Aren't I using the test data set as the input features to test the model on new data it has not seen before?
Hi Justin!
You’re right that when we use
- Training data is used right away: we standardize it, fit the model, and train.
- Test (or new) data is set aside until the model is ready to make predictions. At that point, we prepare it by creating the input DataFrame, standardizing it with the same scaler from training, and then running
So while the data sets exist together from the start, the logical order of operations is still: train on the training set first → then prepare and transform the test set → finally, make predictions.
Hope this helps.
Best,
Ivan
You’re right that when we use
train_test_split , we create both the training and test sets at the same time. The key difference is in when we use them.- Training data is used right away: we standardize it, fit the model, and train.
- Test (or new) data is set aside until the model is ready to make predictions. At that point, we prepare it by creating the input DataFrame, standardizing it with the same scaler from training, and then running
predict .So while the data sets exist together from the start, the logical order of operations is still: train on the training set first → then prepare and transform the test set → finally, make predictions.
Hope this helps.
Best,
Ivan
Right on. I can see that logic. Thanks for taking the time to explain it!
-Justin
-Justin
You're very welcome!
Best,
Ivan
Best,
Ivan
Hey Ivan,
Thank you for all your help. You've been awesome. I'm wondering if you're not too busy to share your expertise on a question from another class. If would be AWESOME if you could help us out! This question has been unanswered since 2021 and I'm running into the same issues as the guys back then. It's related to deep learning with tensor flow 2. Thanks again if you are able to jump in here and help us! The link to this one is below:
https://365datascience.com/q/941ef1ffbe
Thank you again!
-Justin
Thank you for all your help. You've been awesome. I'm wondering if you're not too busy to share your expertise on a question from another class. If would be AWESOME if you could help us out! This question has been unanswered since 2021 and I'm running into the same issues as the guys back then. It's related to deep learning with tensor flow 2. Thanks again if you are able to jump in here and help us! The link to this one is below:
https://365datascience.com/q/941ef1ffbe
Thank you again!
-Justin