Error in location_data.unique()
Hello,
When I reproduce the above code in jupyter, I get the error message below. Thanks very much.
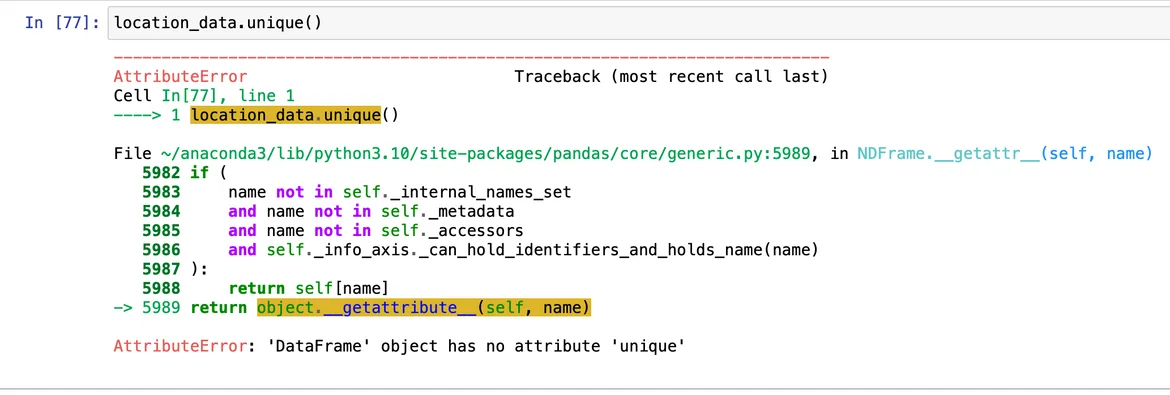
Addendum: Actually, I got error messages every time I used 'unique', as shown below:
Hi Vania!
Thanks for reaching out.
The error DataFrame object has no attribute 'unique' occurs because the unique() function is not a direct attribute of a DataFrame object in pandas.
To get the unique values from a column or Series within a DataFrame, you can use the unique() function on that specific column or Series.
if location_data is a Series object instead of a DataFrame, the unique() function would work without producing the error.
Thus, I assume that earlier in your code you created a DataFrame with the same name. Please try to restart Kernel and re-execute the code cells after creating a Series object in a new document.
Hope this helps.
Best,
Ivan
Hi Ivan,
Thanks for your quick reply. I re-started the kernel, but obtained the same mistake. I did not create a dataFrame before with the same name, I have been copying everything from the video class into jupyter.
I also tried the same code in a different document but obtained the same error messages.
However, as regards it being a Series object or a dataFrame, I did obtain the results below that I don't know how to interpret:
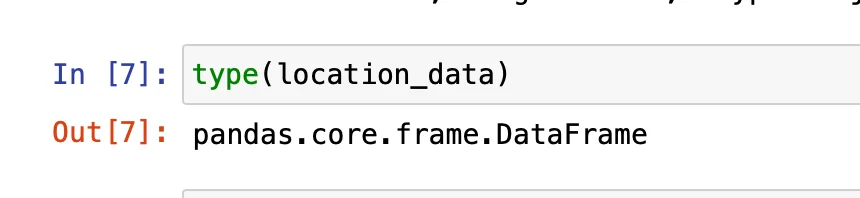

Thanks again. Best, Vânia
Hi Vania!
The reason you have a DataFrame instead of a Series, as shown in the lesson, is because you didn't utilize the squeeze parameter when creating the variable that holds the data from the resources.
When squeeze=True is used, the output is returned as a Series object instead of a DataFrame.
data = pd.read_csv('Location.csv', squeeze = True)
After fixing that, your code should work as intended.
Hope this helps.
Best,
Ivan
after the line:
data = pd.read_csv('Location.csv')
add the line:
data = data.squeeze("columns")
Then check you have a Series and not a DataFrame.
unique() only works on Series. If you do not 'squeee' the columns then pd will create a DataFrame instead of a Series. The video is dated as the attribute 'squeeze = True' has now been deprecated. It would be nice if Data365 added a caption to tell us this. It took me a while to work out what was going on.
Hi Alastair!
Thanks for reaching out.
First of all, please accept my apologies for the terribly delayed response.
You are absolutely right. We've adressed the issue of using the latest method here: https://learn.365datascience.com/courses/working-with-text-files-in-python/python-importing-data-with-the-pandas-squeeze-method/. Please refer to that video and apply it when you need to use the .squeeze() method.
Hope this helps.
Best,
Martin