Nilotpal C.
See all reviews
Skill level:
Duration:
CPE credits:
Accredited

Bringing real-world expertise from leading global companies


Master's degree, Computer Science


Bringing real-world expertise from leading global companies


Bachelor's degree, Data Science

Description
Curriculum
Free lessons

1.1 Introduction
3 min
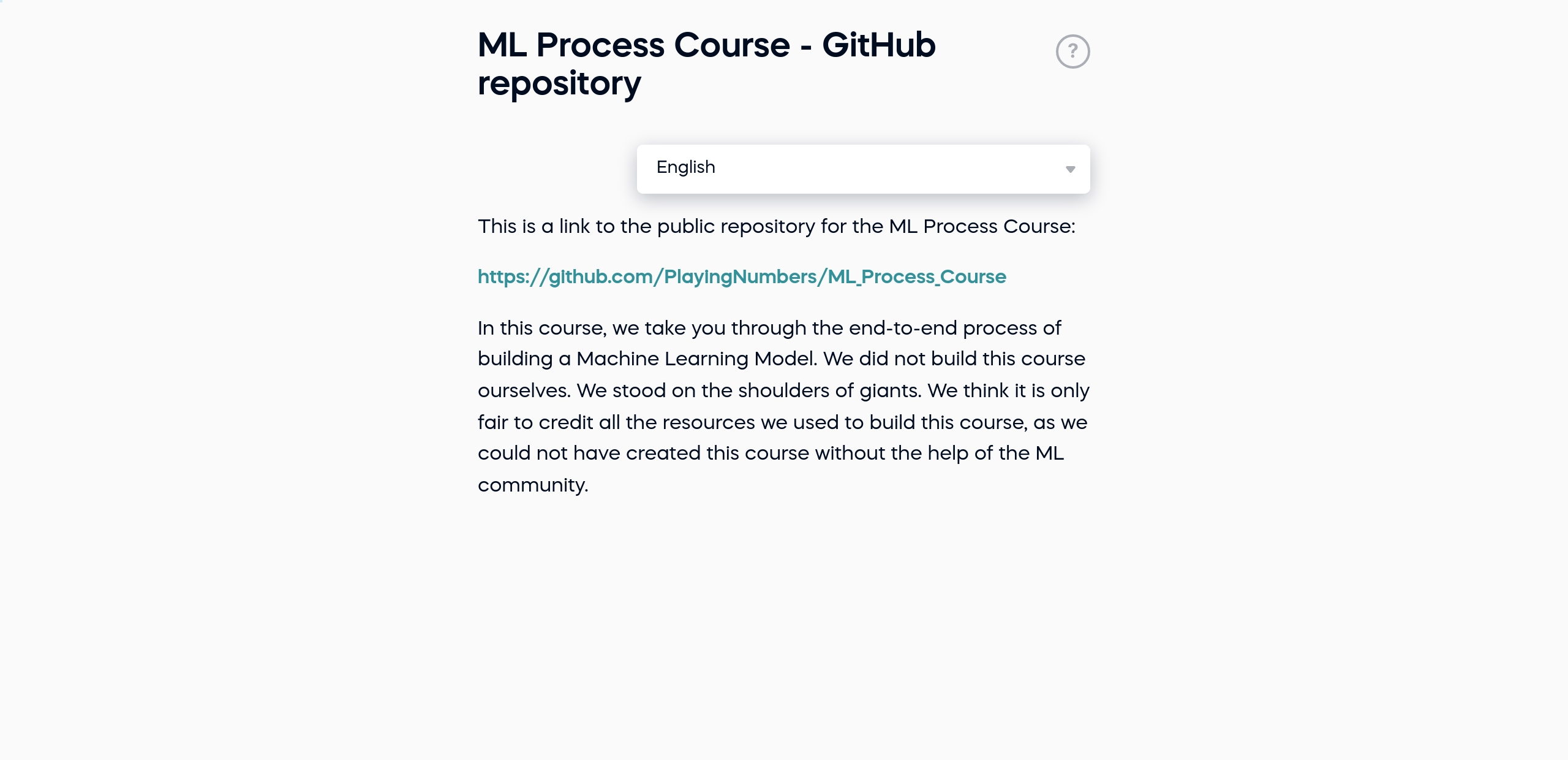
1.2 ML Process Course - GitHub repository
1 min

1.3 Meet your instructors
1 min

1.4 How to use this course
1 min

1.5 Additional resources
1 min

1.6 Environment setup
1 min
9 in 10
of our graduates landed a new AI & data job
9 in 10
people walk away career-ready
94%
of AI and data science graduates
successfully change
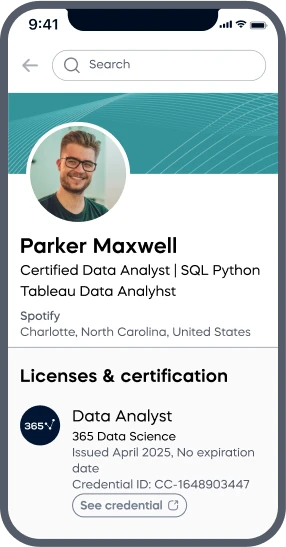
ACCREDITED certificates
Craft a resume and LinkedIn profile you’re proud of—featuring certificates recognized by leading global
institutions.
Earn CPE-accredited credentials that showcase your dedication, growth, and essential skills—the qualities
employers value most.




Certificates are included with the Self-study learning plan.

How it WORKS
Student REVIEWS