In this tutorial, we will focus on databases vs spreadsheets. It is not just Excel users who will benefit from this article. Those of you who do not use Excel regularly will learn the advantages and the disadvantages of using databases or spreadsheets.
If you are familiar with spreadsheets, you might be wondering why databases are even used. Some of you might be users and still imagine an Excel spreadsheet when we talk about tabular data. Please, don’t do that! Data tables, databases, and Excel spreadsheets are different things!

Spreadsheets
Let’s start with a definition.
A spreadsheet is an electronic ledger, i.e., an electronic version of paper accounting worksheets. It was created to facilitate people who needed to store their accounting information in tabular form digitally.

So, it is possible to create tables in a spreadsheet. This is why some people believe spreadsheets and databases are interchangeable, while, in reality, they aren’t.
Common Things Between Databases and Spreadsheets
There are similarities between the two.
- Both can contain a large amount of tabular data.
- Both can use existing data to make calculations.
- Neither spreadsheets nor databases are typically used by a single person, rather many users will work with the data.

What Are the Differences Between Databases and Spreadsheets?
The differences between the two forms of data storage lie in the way these three characteristics are implemented.
The Data They Contain
Data in Spreadsheets
Imagine a spreadsheet. Every cell is treated as a unique entity. It can store any type of information – a date, an integer value, a string name, etc.
Not only can we have diverse types of values in various cells, but we can also apply a specific format to these cells.

Data in Databases
This is not the case with databases. They contain only raw data. Each cell is a container of a single data value. It is the smallest piece of information there is. You must pre-set the type of data contained in a certain field. This feature prevents inadvertent mistakes. For example, in a field containing date values, should you try to insert a string, the software will show an error and you will have the chance to correct yourself.

This won’t happen in Excel – if you insert a string in the column with date values, you won’t obtain an error message and Excel will store the string value.

Storing Data
In a spreadsheet, you can store data in a cell, while in a database, you store it in a record of a table, meaning you must count the records in a table to express how long the data table is, not the number of the cells. And that is it – you cannot pick a font colour or size. All you care about is the information being stored; you don’t care about formatting. Our main goal is to save the numbers.

Calculations in Cells
Another substantial difference is that, in a spreadsheet, different cells can contain calculations, such as functions and formulas. This means, if you want to combine two integers, the result will be stored in another cell. In a database, all calculations and operations are based on the existing data and are done after its retrieval. There is a specific feature, called “views”, similar to the tables, in which you can do a calculation.

These objects also contain columns that can be normal like the ones in the tables or could contain a certain type of calculation. There is no way you can mistake a record of data with a calculation.
Data Integrity
The database features mentioned so far improve data integrity – you can’t store different types of data in the same field, and it is unlikely someone will mistake a data value for an outcome of a calculation, especially in large data sets. Data integrity is why databases are more appropriate when you want to avoid making mistakes.

Creating Relations
Naturally, you might think a spreadsheet can contain multiple worksheets, so one can create tables in the worksheets, and then use the worksheets to create relations between the tables. Why are databases used then? Well, in a spreadsheet, such relations will be logically limited.

Instead of setting up spreadsheets or worksheets, one can set up relations between the tables. This will boost the performance of operations and increase the speed at which you manipulate your dataset.

What Are the Cons of Using Spreadsheets?
Albeit powerful for many circumstances, spreadsheets do have limitations.
Limitations
Excel is incapable of handling over 1 million rows of data. This immediately induces us to look for a solution. Usually, the fix is to use databases, where having 2, 5, or 10 million records is not a problem.

Multi-User Property
Referring to the multi-user property, spreadsheets are lacking. Essentially, every person must update their own spreadsheet with new data. For instance, if there is a new purchase to register or a last name in a table below to correct, every user must make these changes manually.

You would justifiably think Google Docs and the latest versions of Office solve this issue, but they do so only partially. In Google Docs, you might have trouble finding out who changed or deleted information incorrectly, which often leads to a cumbersome situation where people have a hard time organizing their tasks.

What are the Pros of Using Databases vs Spreadsheets?
Controlling Changes
As opposed to that, the first reason why databases are useful is that they provide a stable structure, controlling access permissions and user restrictions. One person can make a change which will be visible to everybody instantly. This feature increases efficiency and data consistency when using databases.

Increased Efficiency
Considering data integrity and data consistency, using databases eliminates duplicate information, which is another way to save space and increase efficiency. Look at the table in the picture below.

The Problem with Spreadsheets
When using databases, you know a certain first and last name corresponds to a unique email address. However, if you are using a spreadsheet flooded with data and you know John McKinley has changed his email, you may change the email address once and accidentally miss updating the same address in another record. This may lead to inadvertent mistakes.

The Solution
This can be avoided by using a relational database - an accredited user only needs to access the table and change John McKinley’s email address there. Just once. Not only will this operation save time, but it will also anticipate inconsistencies. This is yet another reason why databases are more useful when your data can be stored in logically related tables.

Database Terminology
Now, that you know why databases are better than spreadsheets, let’s focus on some database terminology. This is a necessary step that will help you when you start coding in SQL.
What's the Process of Creating a Database?
Let’s go through the entire process of creating a database. Assume our database containing customer sales data has not been set up yet.

So, imagine you are the shop owner and you realize your goods have been selling quite well recently, and you have more than a million rows of data.

What do you need, then? A database! But you know nothing about databases. Who do you call, an SQL specialist? No. You need a database designer.

Database Designers
She will decide how to organize the data into tables and how to set up the relations between these tables. This step is crucial.

If the database design is not perfect from the beginning, your system will be difficult to work with and won’t facilitate your business needs; you will have to start over again. Considering the time, data, and money involved in the process, you want to avoid going back to square 1.

Plotting the Database System
What do database designers actually do? They plot the entire database system on a canvas using a visualization tool. There are two main ways to do that.
Entity-Relationship Diagram
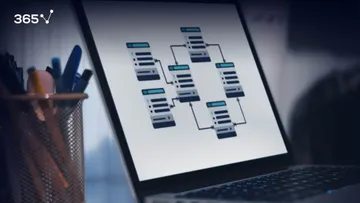
One is drawing an Entity-Relationship diagram, an ER diagram for short. As shown in the picture below, the different figures represent different data entities and the specific relationships we have between entities.

The connections between tables are indicated by lines. This way of representing databases is powerful and professional, but it is complicated. We will not focus in-depth on ER diagrams in these tutorials, but you should know they exist and refer to the process of database design.
Relational Schema
Another form of representation of a database is the relational schema. This is an existing idea of how the database must be organized. It is useful when you are certain of the structure and organization of the database you would like to create.
Let’s see what a relational schema would look like.

It represents a table in the shape of a rectangle. The name of the table is at the top of the rectangle. The column names are listed below.

All relational schemas in a database form the database schema. You can also see lines indicating how tables are related in the database.

Creating the Database
Once the database design process is done, the next step would be to create the database. Up to this moment, it has been ideas, planning, abstract thinking, and design. At this stage, it would be correct to say SQL can be used to set up the database physically, as opposed to contriving it abstractly.

Data Manipulation
It is only then that you can enjoy the advantages of data manipulation. It will allow you to use your dataset to extract business insights that aim to improve the performance and efficiency of the business you are working for. This process is interesting, and, practically, the main part of the tutorials will be related to that.

Important: Well thought-out and carefully designed databases are crucial prerequisites for data manipulation. If we have done good work with these steps, we can write effective queries and navigate a database rather quickly.

Database Management
You will often hear the term database management. It comprises all the steps a business undertakes to design, create, and manipulate its databases successfully.

Database Administration
Finally, database administration is the most frequently encountered job of all. A database administrator provides daily care and maintenance of a database. Her scope of responsibilities is narrower regarding the ones carried out by a database manager, but she is still indispensable for the database department of a company.

Why Databases?
So, what we discussed in this tutorial highlights why databases are a better environment for storing and keeping track of data when working with multiple dimensions and large amounts of data. Spreadsheets have their advantages as well – they are an excellent tool that allows us to carry out extensive analysis. But for the easy retrieval and updating of data, efficiency, data consistency, data integrity, speed, and security, relational databases are definitely the structure to opt for. They can store lots of raw data and are excellent when separating the data from the way it is displayed for analysis.

As you saw, it would be a good idea to stop trying to visualize data tables in the form of spreadsheets. They are different.

Moreover, this tutorial allowed us to learn certain terms we will be using often when dealing with databases. If you are eager to learn more, make sure you jump into the next tutorial where we will explain how meaningful a relational schema can be for you to understand the functioning of a certain database.
***
Eager to hone your SQL skills? Check out our SQL course.
Next Tutorial: SQL Primary Key