Time Series Analysis with Python
Master time series forecasting in Python: Gain solid theoretical knowledge and work with popular time series models such as ARIMA, ARCH, and GARCH
$99.00
Lifetime access
What you get:
- 7 hours of content
- 64 Interactive exercises
- 40 Downloadable resources
- World-class instructor
- Closed captions
- Q&A support
- Future course updates
- Course exam
- Certificate of achievement
Time Series Analysis with Python
$99.00
Lifetime access
What you get:
- 7 hours of content
- 64 Interactive exercises
- 40 Downloadable resources
- World-class instructor
- Closed captions
- Q&A support
- Future course updates
- Course exam
- Certificate of achievement
$99.00
Lifetime access
$99.00
Lifetime access
What you get:
- 7 hours of content
- 64 Interactive exercises
- 40 Downloadable resources
- World-class instructor
- Closed captions
- Q&A support
- Future course updates
- Course exam
- Certificate of achievement
What You Learn
- Employ proven time series techniques to make reliable forecasts
- Master the principles of manual model selection to select the most appropriate statistical models based on specific scenarios
- Be able to normalize data to compare and analyse different time series
- Apply key time series models in Python (AR, MA, ARMA, ARIMA, ARCH, GARCH) to predict credit risk
- Visualize important types of time series data such as white noise and random walk
- Secure a competitive edge over other candidates when applying for finance roles
Top Choice of Leading Companies Worldwide
Industry leaders and professionals globally rely on this top-rated course to enhance their skills.
Course Description
Data Science mainly relies on working with two types of data - cross-sectional and time series. This course will help you master the latter by introducing you to the ARMA, seasonal, integrated, MAX and volatility models, as well as show you how to forecast them into the future
Learn for Free

1.1 What does the Course Cover
4 min

2.1 Setting up the Environment
1 min
2.2 Installing the Necessary Packages
1 min

3.1 Introduction to Time Series Data
4 min
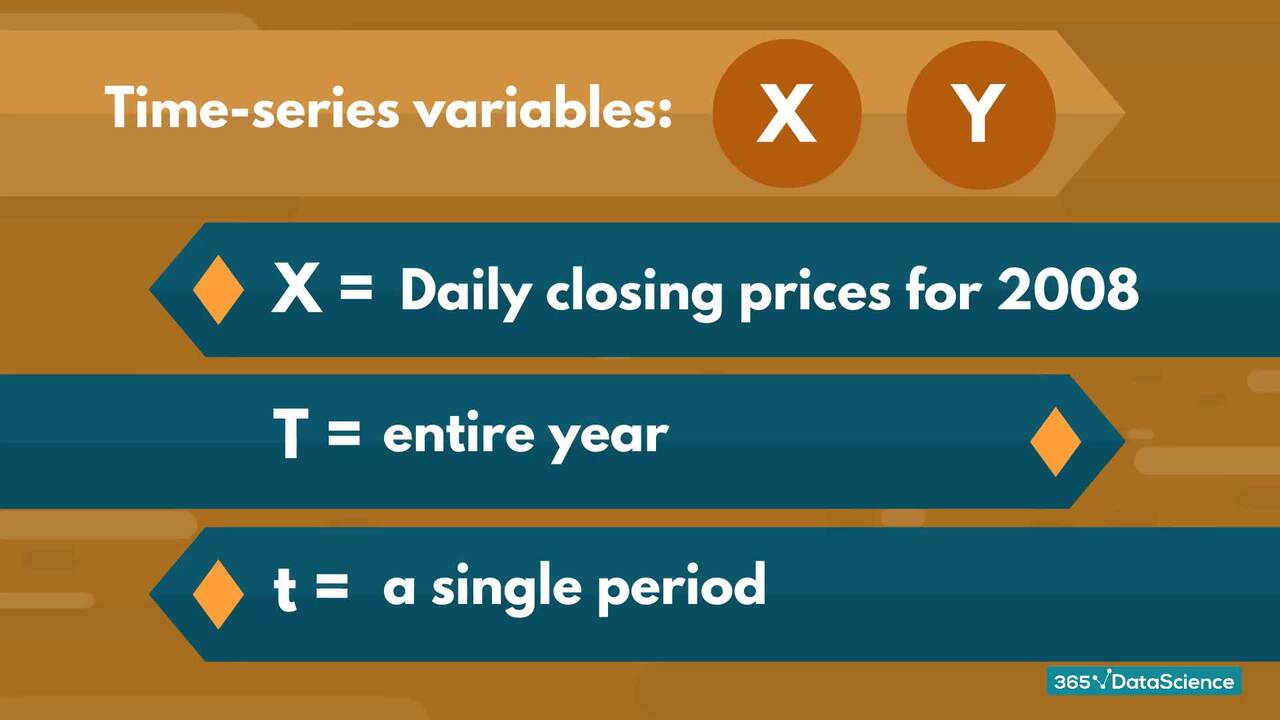
3.2 Notation for Time Series Data
1 min
3.3 Peculiarities of Time Series Data
3 min
Interactive Exercises
Practice what you've learned with coding tasks, flashcards, fill in the blanks, multiple choice, and other fun exercises.
Practice what you've learned with coding tasks, flashcards, fill in the blanks, multiple choice, and other fun exercises.








Curriculum
Topics
Course Requirements
- You need to complete an introduction to Python before taking this course
- Basic skills in statistics, probability, and linear algebra are required
- It is highly recommended to take the Machine Learning in Python course first
- You will need to install the Anaconda package, which includes Jupyter Notebook
Who Should Take This Course?
Level of difficulty: Intermediate
- Aspiring data scientists
- Current data scientists who are passionate about acquiring specialized knowledge
Exams and Certification
A 365 Data Science Course Certificate is an excellent addition to your LinkedIn profile—demonstrating your expertise and willingness to go the extra mile to accomplish your goals.

Meet Your Instructor


A Hamilton College graduate, Viktor has a strong analytics background, focusing on the fields of Statistics, Econometrics, Financial Time-Series Econometrics, and Behavioral Economics. Viktor’s coding experience is rather diverse – from working with C, C++, and Python through to the more math/econ-oriented MATLAB and STATA. He has been fascinated by coding algorithms since the age of 11 and describes himself as a “Bachelor of Science and overall cool guy”. We couldn’t agree more. Some of Viktor’s personal achievements include developing a model for forecasting transfer prices of soccer players across Europe’s top divisions and Stock Market Indexes analysis on the effects of contagion on the effectiveness of international portfolio diversification.
What Our Learners Say



365 Data Science Is Featured at
Our top-rated courses are trusted by business worldwide.































